Algorithm
为了构建自己的代码库,从本周开始每周实现一个到两个经典的强化学习算法,并做一定笔记对该算法进行记录。
这周记录的算法是Prioritied Experience Replay[1],该算法是Google在16年提出的,基本思想很简单,就是为了增加对TD-error比较大的experience的训练次数,得以让网络更好拟合环境的Reward空间。 最简单的方法是将experience按照TD-error进行排序,然后优先训练TD-error较大的experience。但这样的方法很容易导致一些TD-error较小的experience很难被训练到,容易导致过拟合。
Google提出的方法是利用了线段树的存储和查找方式。这个方法之前在数据结构中没有遇到,所以本文更多的笔墨会说明这种存储方式。 先看算法的完整伪代码:

(1) 首先可以注意到,本算法基于DQN做改进。对于第个experience,被采样的概率为,其中为第个样本的优先级(priority),决定了TD-error作为优先级的程度,为的小数。本文中采取了两种计算的方法:
-
其中一种是proportional prioritization:,其中为TD-error的绝对值,为一个很小正数,防止某些TD-error很小的experience很少被采样。
-
另一种是rank-based prioritization:。为第个experience的TD-error在memory中的排序位置。 实验证明前者更佳。
(2) 因为本算法采取Priorited的采样方式,改变了网络对每个样本的更新频率,既这种采样的分布带来了偏差。为了修复或者缓解这种偏差,本文还采用了importance-sampling (IS) weights的方式进行矫正:
这里逐渐趋近于0,而逐渐趋向于1,在更新网络时采用代替。另外对所有的做归一化,都乘以. 剩下的部分跟DQN的更新保持一致。
Sample Methods
为了提高采样的效率,该算法采用了线段树这种数据结构来存储数据。具体代码可参考openai/baselines,下面重点讲一下segment tree这种数据结构。
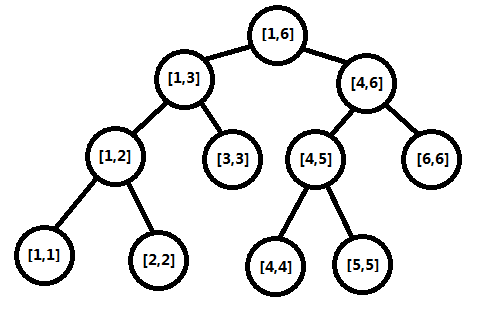
Segment Tree Basic Concept
线段树是一种二叉搜索树,即每个结点最多有两棵子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。线段树的每个结点存储了一个区间(线段),故而得名。
如图所示,表示的是一个[1, 6]的区间的线段树结构,每个结点存储一个区间(注意这里的存储区间并不是指存储这个区间里面所有的元素,而是只需要存储区间的左右端点即可),所有叶子结点表示的是单位区间(即左右端点相等的区间),所有非叶子结点(内部结点)都有左右两棵子树,对于所有非叶子结点,它表示的区间为[l, r],那么令mid为(l + r)/2的下整,则它的左儿子表示的区间为[l, mid],右儿子表示的区间为[mid+1, r]。基于这个特性,这种二叉树的内部结点,一定有两个儿子结点,不会存在有左儿子但是没有右儿子的情况。
基于这种结构,叶子结点保存一个对应原始数组下标的值,由于树是一个递归结构,两个子结点的区间并正好是父结点的区间,可以通过自底向上的计算在每个结点都计算出当前区间的最大值。
需要注意的是,基于线段树的二分性质,所以它是一棵平衡树,树的高度为。
What kind of data should be stored?
了解线段树的基本结构以后,看看每个结点的数据域,即需要存储哪些信息。
首先,既然线段树的每个结点表示的是一个区间,那么必须知道这个结点管辖的是哪个区间,所以其中最重要的数据域就是区间左右端点[l, r]。然而有时候为了节省全局空间,往往不会将区间端点存储在结点中,而是通过递归的传参进行传递,实时获取。
再者,以区间最大值为例,但线段树不一定要存储最大值,可以存储你任意希望的存储的数据,比如Prioritized Experience Replay中存储的就是priority(code),每个结点除了需要知道所管辖的区间范围[l, r]以外,还需要存储一个当前区间内的最大值max。
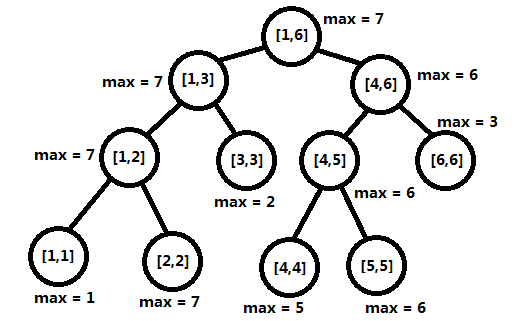
以数组A[1:6] = [1 7 2 5 6 3]为例,建立如图的线段树,叶子结点的max域为数组对应下标的元素值,非叶子结点的max域则通过自底向上的计算由两个儿子结点的max域比较得出。这是一棵初始的线段树,接下来讨论下线段树的询问和更新操作。
在询问某个区间的最大值时,我们一定可以将这个区间拆分成个子区间,并且这些子区间一定都能在线段树的结点上找到,然后只要比较这些结点的max域,就能得出原区间的最大值了,因为子区间数量为,所以时间复杂度是。
更新数组某个元素的值时我们首先修改对应的叶子结点的max域,然后修改它的父结点的max域,以及祖先结点的max域,换言之,修改的只是线段树的叶子结点到根结点的某一条路径上的max域,又因为树高是,所以这一步操作的时间复杂度也是的。
Code Represantation of Segment Tree
接下来讨论一下结点的表示法,每个结点可以看成是一个结构体指针,由数据域和指针域组成,其中指针域有两个,分别为左儿子指针和右儿子指针,分别指向左右子树;数据域存储对应数据,根据情况而定(如果是求区间最值,就存最值max;求区间和就存和sum),这样就可以利用指针从根结点进行深度优先遍历了。
以下是简单的线段树结点的C++结构体:
struct treeNode {
Data data; // 数据域
treeNode *lson, *rson; // 指针域
}*root;
实际计算过程中,还有一种更加方便的表示方法,就是基于数组的静态表示法,需要一个全局的结构体数组,每个结点对应数组中的一个元素,利用下标索引。
例如,假设某个结点在数组中下标为,那么它的左儿子结点的下标就是,右儿子结点的下标就是(类似于一般数据结构书上说的堆在数组中的编号方式),这样可以将所有的线段树结点存储在相对连续的空间内。之所以说是相对连续的空间,是因为有些下标可能永远用不到。

还是以长度为6的数组为例,如图所示,红色数字表示结点对应的数组下标,由于树的结构和编号方式,导致数组的第10、11位置空缺。
这种存储方式可以不用存子结点指针,取而代之的是当前结点的数组下标索引,以下是数组存储方式的线段树结点的C++结构体:
struct treeNode {
Data data; // 数据域
int pid; // 数组下标索引
int lson() { return pid << 1; }
int rson() { return pid<<1|1; } // 利用位运算加速获取子结点编号
}nodes[ MAXNODES ];
接下来我们关心的就是MAXNODES的取值了,由于线段树是一种二叉树,所以当区间长度为2的幂时,它正好是一棵满二叉树,数组存储的利用率达到最高(即100%),根据等比数列求和可以得出,满二叉树的结点个数为,其中为区间长度(由于C++中数组长度从0计数,编号从1开始,所以MAXNODES要取)。那么是否对于所有的区间长度n都满足这个公式呢?答案是否定的,当区间长度为6时,最大的结点编号为13,而公式算出来的是12(2*6)。
为了保险起见,我们可以先找到比n大的最小的二次幂,然后再套用等比数列求和公式,这样就万无一失了。举个例子,当区间长度为6时,MAXNODES = 2 * 8;当区间长度为1000,则MAXNODES = 2 * 1024;当区间长度为10000,MAXNODES = 2 * 16384。
The Basic Operation of Segment Tree
线段树的基本操作包括构造、更新、询问,都是深度优先搜索的过程。
1、构造
线段树的构造是一个二分递归的过程,封装好了之后代码非常简洁,总体思路就是从区间[1, n]开始拆分,拆分方式为二分的形式,将左半区间分配给左子树,右半区间分配给右子树,继续递归构造左右子树。 当区间拆分到单位区间时(即遍历到了线段树的叶子结点),则执行回溯。回溯时对于任何一个非叶子结点需要根据两棵子树的情况进行统计,计算当前结点的数据域。
void segtree_build(int p, int l, int r) {
nodes[p].reset(p, l, r); // 注释1
if (l < r) {
int mid = (l + r)/2;
segtree_build(p<<1, l, mid); // 注释2
segtree_build(p<<1|1, mid+1, r); // 注释3
nodes[p].updateFromSon(); // 注释4
}
}
注释1:初始化第p个结点的数据域,根据实际情况实现reset函数 注释2:递归构造左子树 注释3:递归构造右子树 注释4:回溯,利用左右子树的信息来更新当前结点,updateFromSon这个函数的实现需要根据实际情况进行求解,与数据域存储的数据有关。 构造线段树的调用如下:segtree_build(1, 1, n);
2、更新
线段树的更新是指更新数组在[x, y]区间的值,具体更新这件事情是做了什么要根据具体情况而定,可以是将[x, y]区间的值都变成val(覆盖),也可以是将[x, y]区间的值都加上val(累加)。
更新过程采用二分,将[1, n]区间不断拆分成一个个子区间[l, r],当更新区间[x, y]完全覆盖被拆分的区间[l, r]时,则更新管辖[l, r]区间的结点的数据域。
void segtree_insert(int p, int l, int r, int x, int y, ValueType val) {
if( !is_intersect(l, r, x, y) ) { // 注释1
return;
}
if( is_contain(l, r, x, y) ) { // 注释2
nodes[p].updateByValue(val); // 注释3
return;
}
nodes[p].giveLazyToSon(); // 注释4
int mid = (l + r)/2;
segtree_insert(p<<1, l, mid, x, y, val); // 注释5
segtree_insert(p<<1|1, mid+1, r, x, y, val); // 注释6
nodes[p].updateFromSon(); // 注释7
}
注释1:区间[l, r]和区间[x, y]无交集,直接返回 注释2:区间[x, y]完全覆盖[l, r] 注释3:更新第p个结点的数据域 注释4:设置lazy-tag(后面会提) 注释5:递归更新左子树 注释6:递归更新右子树 注释7:回溯,利用左右子树的信息来更新当前结点 更新区间[x, y]的值为val的调用如下:segtree_insert(1, 1, n, x, y, val);
3、询问
线段树的询问和更新类似,大部分代码都是一样的,只有红色部分是不同的,同样是将大区间[1, n]拆分成一个个小区间[l, r],这里需要存储一个询问得到的结果ans,当询问区间[x, y]完全覆盖被拆分的区间[l, r]时,则用管辖[l, r]区间的结点的数据域来更新ans。
void segtree_query (int p, int l, int r, int x, int y, treeNode& ans) {
if( !is_intersect(l, r, x, y) ) {
return ;
}
if( is_contain(l, r, x, y) ) {
ans.mergeQuery(p); // 注释1
return;
}
nodes[p].giveLazyToSon();
int mid = (l + r)/2;
segtree_query(p<<1, l, mid, x, y, ans);
segtree_query(p<<1|1, mid+1, r, x, y, ans);
nodes[p].updateFromSon(); // 注释2
}
注释1:更新当前解ans,会在第四节进行详细讨论 注释2:和更新一样的代码,不再累述
4.lazy-tag
在区间求和问题中,因为涉及到区间更新和区间询问,如果更新和询问都只遍历到询问(更新)区间完全覆盖结点区间的话,会导致计算遗留,举个例子来说明。
用一个数据域sum来记录线段树结点区间上所有元素的和,初始化所有结点的sum值都为0,然后在区间[1, 4]上给每个元素加上4,如图所示:

图中[1, 4]区间完全覆盖[1, 3]和[4, 4]两个子区间,然后分别将值累加到对应结点的数据域sum上,再通过回溯统计sum和,最后得到[1, 6]区间的sum和为16,看上去貌似天衣无缝,但是实际上操作一多就能看出这样做是有缺陷的。例如当我们要询问[3, 4]区间的元素和时,在线段树结点上得到被完全覆盖的两个子区间[3, 3]和[4, 4],累加区间和为0 + 4 = 4,如图所示:

这是因为在进行区间更新的时候,由于[1, 4]区间完全覆盖[1, 3]区间,所以我们并没有继续往下遍历,而是直接在[1, 3]这个结点进行sum值的计算,计算完直接回溯。等到下一次访问[3, 3]的时候,它并不知道之前在3号位置上其实是有一个累加值4的,但是如果每次更新都更新到叶子结点,就会使得更新的复杂度变成,违背了使用线段树的初衷,所以这里需要引入一个lazy-tag的概念。
所谓lazy-tag,就是在某个结点打上一个“懒惰标记”,每次更新的时候只要更新区间完全覆盖结点区间,就在这个结点打上一个lazy标记,这个标记的值就是更新的值,表示这个区间上每个元素都有一个待累加值lazy,然后计算这个结点的sum,回溯统计sum。
当下次访问到有lazy标记的结点时,如果还需要往下访问它的子结点,则将它的lazy标记传递给两个子结点,自己的lazy标记置空。
这就是为什么在之前在讲线段树的更新和询问的时候有一个函数叫giveLazyToSon了。
openai/baselines中的python实现有所不同,但基本思想类似。python实现中没有树的构建过程,而是在memory一边存储的过程中进行树的构建。reduce函数其实为查询函数。