由于最近科研任务需要,开始关注meta learning的研究进展,发现内容繁多,方法也很多,所以写一篇调研报告帮助梳理思路。
Meta learning领域经常应用于Few-shot learning的问题,也就是如何在小数据量的问题上使模型快速收敛,这一点不管是在deep learning或者reinforcement learning领域都很重要。
那么,meta-learning 和 few-shot learning 的动机是什么呢?当我们没有足够多的标注数据来提供训练时,我们往往想从其他的无标注数据(无监督学习)、多模态数据(多模态学习)和多领域数据(领域迁移、迁移学习)里来获得更多帮助。在这种动机的驱动下,few-shot learning 便是希望针对一组小样本,得到一个能学习到很好的模型参数的算法。而如果我们能用端对端的方式学习到这种算法,那么就可以称为 meta-learning 或者 learning to learn。
Meta Learning的实现方法并不单一,只要是具有快速学习功能的算法都是meta learning相关的方法,下面做了一个从方法类型和研究领域做了一个大概的归类。
Metric Learning
度量学习的方法是对样本间距离分布进行建模,使得属于同类样本靠近,异类样本远离。简单地,我们可以采用无参估计的方法,如KNN。KNN虽然不需要训练,但效果依赖距离度量的选取。但目前比较好的方法是通过学习一个端到端的最近邻分类器,它同时受益于带参数和无参数的优点,使得不但能快速的学习到新的样本,而且能对已知样本有很好的泛化性。
Siamese Neural Network
比较早的工作是15年NIPS的 Siamese neural network[16],如Fig 1所示,输入分为两个部分,其中一个输入是support set中的数据,另外一个是要测试的数据,最后输出两个输入是同一个类型的概率,遍历所有support set后,概率大的为预测类型。
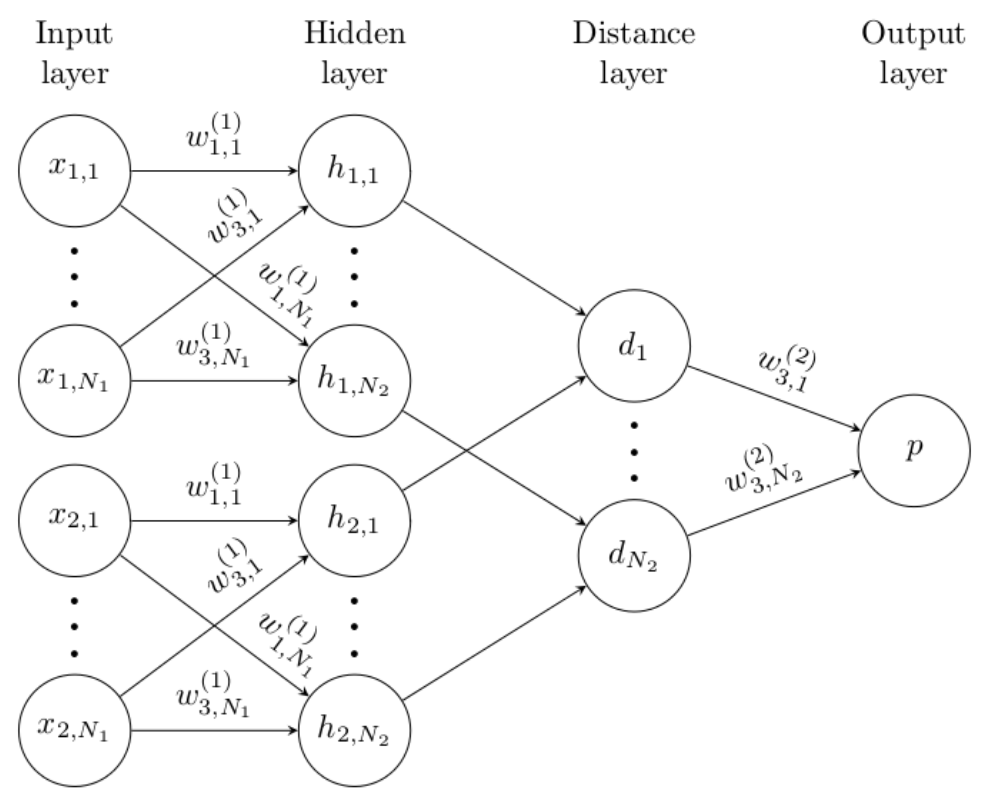
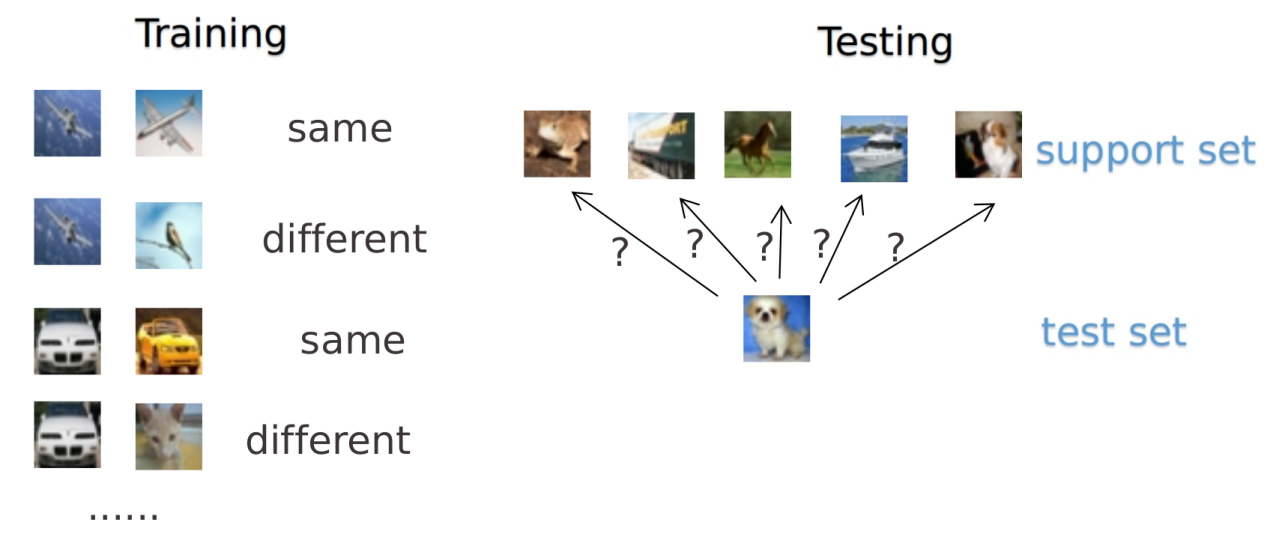
Siamese neural network较早得提出了在feature map层面对比图片来提升few-shot问题的性能,比较的功能也是由网络学习获得的。
17ICCV上Facebook发表的[18]也是通过先学习feature map层面的特征,再通过网络学习feature map的差异来解决few-shot learning问题。
Matching Network
基于比较的思想,[1]提出了更加合理的Matching方案,作者引入了attention机制和memory机制。
他们把问题建模成:
其中为support set,为attension机制。
这里的attention机制是先将输入与support set的分别做embeding(分别用表示),然后计算cosine distance ,再输入到softmax中归一化到0-1,即下式所示:
attention机制可以理解为最终对于距离的的响应会更多得被考虑,那么这样embeding操作就决定了最后attention机制的响应。作者认为对于单个样本的embeding都应该考虑support set 的情况。所以修改为。
- 对于,作者将support set中的样本看作一个序列,利用BiLSTM作为embeding的网络结构,对每一个进行编码。
- 对于,作者利用一个带有attention的LSTM结构(具体细节看论文Appendix)
这种embeding使得网络能够忽视一些不重要的类别,在性能上也得到了很大的提升,也是该领域Matching网络的基础。
Prototypical Network
17年NIPS,[2]提出了一种Prototypical Network,该网络的思路很简单,对于每个类型学习一个原型表达(Prototy),然后对于测试样本计算与这些原型的距离即可。如Fig 3所示

伪代码如下: 代码中的采用了Bregman divergence,实验证明效果优于cosine distance。

Gradient Descent
基于梯度的方法中,最流行的meta learning方法如Google在16年发表的[3],这类方法会构建一个meta learner和learner两个部分,meta learner负责学习一个更新learner的策略或者直接是网络参数

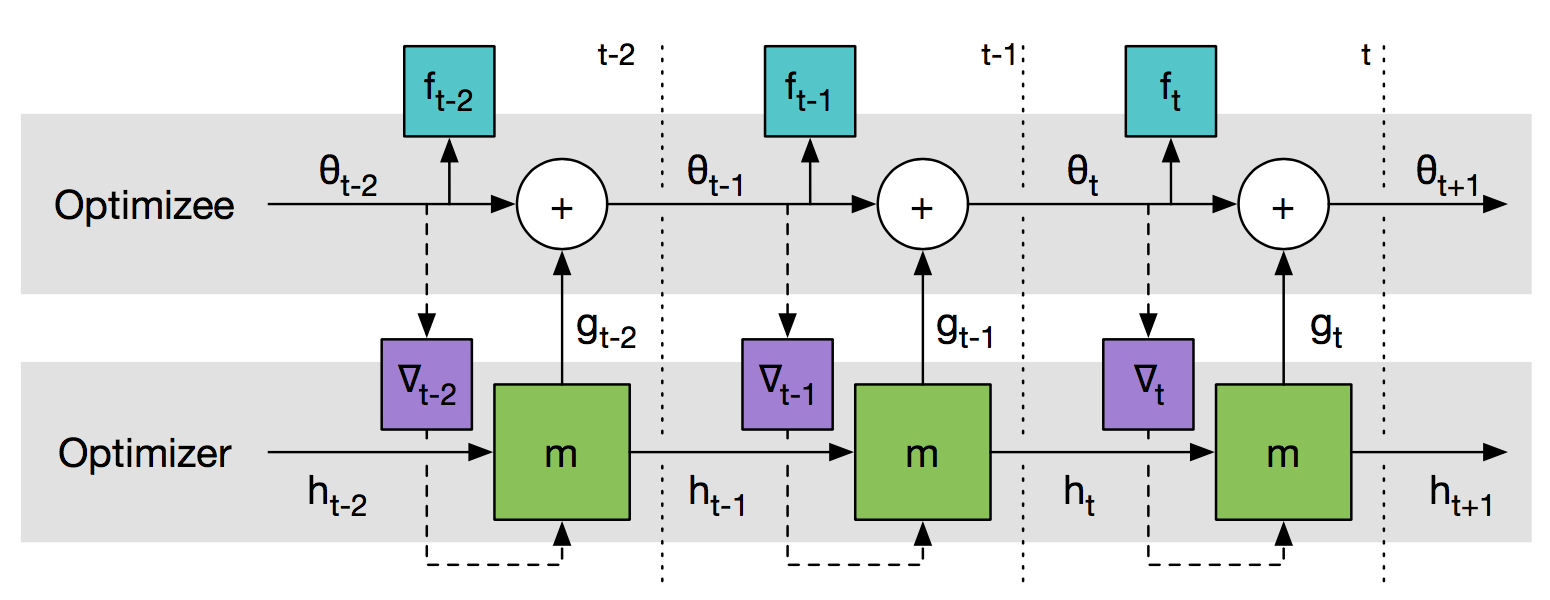
如Fig 4所示,作者训练了一个两层的LSTM的优化器,输入是网络参数在Loss Function上梯度,然后Optimizer输出网络参数的增量。具体如Fig 5所示,这样其实相当于将learner的learning rate也省去了,直接学习对每个参数的数值。从实验结果上看,这样的方法甚至超过了例如adam,rmsprop等常用的优化器。另外类似的工作是17NIPS的hypernetwork[14],方法也是用一个网络产生另外一个网络的权值,同时实验了CNN和RNN在meta learning上的效果。
而[15]将这样的框架应用到了few shot问题中并取得了不错的效果。具体算法如下,论文的使用的meta learning算法与[3]类似,同样是训练一个meta learner和一个用于分类的learner网络,不同之处是[15]把这种框架在few shot问题上做了扩展,算法的优化目标是得到一个对于few shot问题最优的meta learner,即最优的参数

[3],[14],[15]都是从deep learning的角度来求解最优的更新的策略,而[12]从强化学习的角度来解释更新策略的求解,算法模型如下:

作者将优化问题看作一个马尔可夫过程,并建模了优化问题一般的形式,把问题转化为学习一个优化策略,策略网络的输出即梯度下降的结果,也就是learner网络参数的增量。
除了上述meta learner和learner这种两个网络的模型,在17年ICML上UC Berkeley提出一种免模型的meta learning方法[4],该方法不需要一个meta learner来指导learner的更新,他们的出发点是学习一个对于各种同类型任务都非常敏感的参数模型,在这样一种参数情况下,对于任意任务的Loss Function都能很快收敛,可以认为是学习一个对于特定问题的最优网络初始化。具体算法如下:

该算法的思想是学习一个对于各种同质任务很敏感的初始化网络参数,如Fig 6所示。这个网络参数可以在任意Loss Function的第一次迭代中快速收敛。算法流程:
- 首次构建一个同质任务的任务库,可以理解为meta learning的数据集,用于后面采样。
- 然后中这些任务上做单次更新得到并记录。
- 最后通过计算meta learning的Loss Function,更新初始化参数。

目前在meta learning领域最流行的框架就是一个meta learner和一个learner的模型,这样的结构相当于生成网络参数,这种结构优点是对于网络的每一个权值都能自适应一个特定的更新增量,但这种结构的对于很深的大规模网络需要训练很多meta learner,训练复杂度高。而[12]的方法在一定程度上解决了这个问题。这几篇论文的测试数据集都有不同,所以暂时没有性能对比。
Memory-Augmented Network
Meta Learning领域一种基于记忆增强神经网络的方法,这种方法通过加入可读写的外部存储器层,实现用极少量新观测数据就能有效对模型进行调整,从而快速获得识别未见过的目标类别的meta-learning能力,也就是可以利用极少量样本学习。
[5]将这种记忆增强神经网络[18]用到了meta learning的领域,并提出了新的存储读写更新策略——LRUS(Least Recently Used Access),每次写操作只选择最少被用到的存储位置或者最近被用的存储位置。这样的策略完全由内容决定,不依赖于存储的位置。
这种方式能够起作用的原因是网络的记忆功能用一个外部存储来代替,迫使网络去学习一些high-level的信息。
另外一篇很重要的记忆增强神经网络的论文[6]获得了17ICLR的oral,作者是李飞飞的学生。作者提出了一种用于深度学习的大规模终身记忆模块,利用了快速最近邻算法加快了查询效率。一个新的样本出现,先在memory中找到最近邻特征,如果类别不同,就在存放最久的样本中随机选取一个位置存放新的样本特征,因为这个样本更加rare;如果类别相同,则合并两个特征。具体做法如Fig 7。

综上,[5]是记忆增强网络这few shot问题上的首次应用,论文创新性很高,直接将网络的记忆功能用一个可查询的存储结构代替。[6]在这个基础上对速度,匹配方法做了改进。这种方法的优势是可解释性比较强,网络的记忆部分不再只由LSTM的参数拟合,但缺点就是维护一个很大的memory在某些问题上成本很高,对速度要求高的场景也很难适应。
Semi-Supervised Learning
元学习以上解决的问题都为监督学习的问题,也就是测试集的样本类型,在训练集中都出现过。而18ICLR上的一篇论文[7]在Prototypical Network[2]的基础上做了改进,提出了从训练集中未打标签的数据上学习prototype。
论文中训练集合分为,分别表示标注数据集和未标注数据集。有标注样本为,无标注样本为,类别中心记为,特征提取网络为。 在[2]中,测试样本类别在训练集中肯定出现过,所以可以定义:
但在半监督问题里面并不是所有测试类别都在训练集中出现过,因此基于聚类的思想,作者提出了三种聚类方式来利用未标注数据。
- soft K-Means
在[2]中其实可以看作计算所有同类别的中心,那么对于未标注数据并未利用,如下图。所以作者利用以下公式,将未标注数据也纳入考虑。

- soft K-Means with cluster**
soft k-means虽然将未标注数据也利用上了,但是未标注的数据类别并不一定存在于训练数据类别中,我们称这种类别为distractor class,那么按照soft k-means的做法就会污染其他正确类别的中心估计。为了处理这种情况,作者认为distractor class类别中心始终在原点:
此外再考虑引进类别半径表示类内样本的不一致性(为了方便起见,标注类别半径,只学习无标注样本类别半径。
- masked soft K-Means
在soft K-Means with cluster中,所有的distractor class都被看作同一类,这显然是不合理的,作者利用了mask的思想,也就是说未标注数据对于不同类别的中心计算贡献应该有所区别,而这个区别作者利用一个全连接网络来学习。
定义样本到类别的距离:
另外再用MLP学习两个阈值
然后是聚类中心的更新公式:
目前meta learning研究最多的任务是few shot问题,半监督学习目前只有[7]在这方面做了工作,作者很好得利用聚类的思想在[2]上做了改进,从实验效果上也取得了3个百分点的提高。
Reinforcement Learning
强化学习领域最大的问题是训练难度大,目前在不同强化学习问题上都需要重新训练网络,这为强化学习投入实际应用,例如无人驾驶等需要快速适应的场景带来难度,而元学习在快速学习方面有独特的优势,所以近年开始出现元学习与强化学习的结合。
Multitask Actor-Mimic Network
16年ICLR上[9]从网络优化目标的角度,希望一个agent能够学习多个学习任务的策略,即学习不同任务之间的共通点。首先,对于第个任务的policy objective为如下形式:
其中为Multitask Actor-Mimic Network的策略,这个为学习多任务共通性的参数。
另外一个部分是对于不同任务的适应网络,其中和是全连接网络的输出,对于第个任务由网络来学习到的映射,是第个任务的参数。
通过这种方式,迫使学习到不同任务之间的共通性,加快强化学习在不同任务上的训练。
The Family of Tasks
不同于[9],DeepMind的一篇工作[19]旨在解决某类类似的强化学习问题。论文出发点是近年来循环卷积网络在meta learning领域有比较多的应用,也取得不错的效果,作者希望能把这种模式应用到强化学习上。
作者对于在A3C算法上进行了实验,实验的环境比较简单,主要是老虎机问题和迷宫环境。
作者的改进主要有三点:
- 将meta learning的循环卷积网络用强化学习训练; (其实之前也有类似网络用于强化学习)
- 构造了一个有相关任务的训练集;
- 将action,reward也用于网络输入,如下图:

Nonstationary Environment
强化学习一般都是针对某特定环境训练一个策略模型,而实际应用中有很多环境在随时间改变的情况,即Nonstationary Environment。18ICLR上openai的论文[8]利用meta learning解决在非静态环境和竞争环境上的强化学习问题,并获得了best paper。在非静态环境上应用强化学习主要的难点是非静态环境不能像静态环境一样提供充足的样本供强化学习训练,所以强化学习模型必须迅速适应环境变化,而[4]在强化学习优化上已经做了一定的改进,[8]将MAML框架扩展到连续变化的环境上,如下图所示,(a)是MAML的结构,MAML只对第一步做更新,(b)为作者的模型,可以看出策略和任务都是连续变化的。

作者将强化学习的reward取反作为MAML中的loss function ,在连续非静态环境中,问题转化为优化:
其中
由为参数的策略决定,由为参数的策略决定。
这个Loss function可由policy gradient优化,所以策略更新可写为如下形式:
而,实际上,在训练中,作者每一步使用的都是,原因是有利于收敛,具体算法如下:

可以看出算法的目标是学习最优的初始化策略参数和做某非静态环境下的,而在执行阶段,是通过检测是否有新的任务到来决定是否转化策略的,也就是说对于环境的变化仍然由作者控制的,为某种特定变化下的最优,而不是自适应得对所有的环境变化作出反应。
综上,强化学习因为训练样本需求大,而meta learning在解决小样本训练上有显著的成功,所以考虑将两者结合,但是目前强化学习与meta learning结合还处于起步阶段,都在gym环境或者自己定义的简单环境上进行测试。强化学习与meta learning结合主要有三种任务:(1)对于任意强化学习;(2)对于同一个任务设置不同参数,构造一个任务簇;(3)动态环境或者竞争环境。结合的基本思想也是迫使强化学习agent的权值不要在一个任务上拟合,而是拟合到一个在更多任务上有泛化能力的权值上。
Reference
1.Matching Networks for One Shot Learning [code1,code2]
2.Prototypical Networks for Few-shot Learning [code]
3.Learning to learn by gradient descent by gradient descent [code]
4.Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks [code1,code2]
5.Meta-Learning with Memory-Augmented Neural Networks [code1,code2]
6.Learning to Remember Rare Events [code1,code2]
7.Meta-Learning for Semi-Supervised Few-Shot Classification [code]
8.Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments
9.Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
10.Meta Reinforcement Learning with Latent Variable Gaussian Processes
11.Learning Neural Network Policies with Guided Policy Search under Unknown Dynamics
12.Learning to Optimize
13.Using Fast Weights to Attend to the Recent Past
14.HyperNetworks
15.Optimization as a Model for Few-Shot Learning [code]
16.Siamese neural networks for one-shot image recognition
17.Neural Turing Machines
18.Low-shot Visual Recognition by Shrinking and Hallucinating Features
19.Learning to reinforcement learn[code]
20.Learning to Compare: Relation Network for Few-Shot Learning [code]
21.GitHub - floodsung/Meta-Learning-Papers: Meta Learning / Learning to Learn / One Shot Learning / Few Shot Learning